分布式系统
分布式系统
课程: MIT 6.824
1 简介
分布式系统设计的挑战:
- 并发(Concurrency)
- 局部性错误(Partial Faults)
- 性能(Performance)
分布式系统的基础设施(Infrastructure): --> 抽象
- 存储(Storage)
- 通信(Communication)
- 计算(Computing)
重点在于如何将这些部分构建为抽象接口, 让用户对其是否为分布式系统无感知, 感知上认为是非分布式系统.
即: 复杂行为 --> 简单行为.
分布式系统基础设施的实现:
- RPC(Remote Procedure Call): 隐藏不可靠网络通信过程.
- Threads/Routines & Concurrency Control: 结构化并发编程方式.
分布式系统的性能问题:
- 可扩展性(Scalability): 2 倍资源 --> 2 倍性能(简单实现加钱就能加服务).
分布式系统的容错性(Fault Tolerance):
- 隐藏错误处理过程, 否则会有过多的错误需要手动处理.
- 可用性(Availability): 提供范围内可控的容错.
- 可恢复性(Recoverability): 出现错误可以恢复到正常状态.
容错性保证:
- 非易失性存储(Non-volatile Storage): 持久化存储及其管理设备
- 副本(Replication): 不同副本所在的节点物理环境应该隔离, 避免出现相同的故障.
分布式系统中的一致性问题:
- 强一致性
- 弱一致性: 更多研究如何使弱一致性对应用更可用.
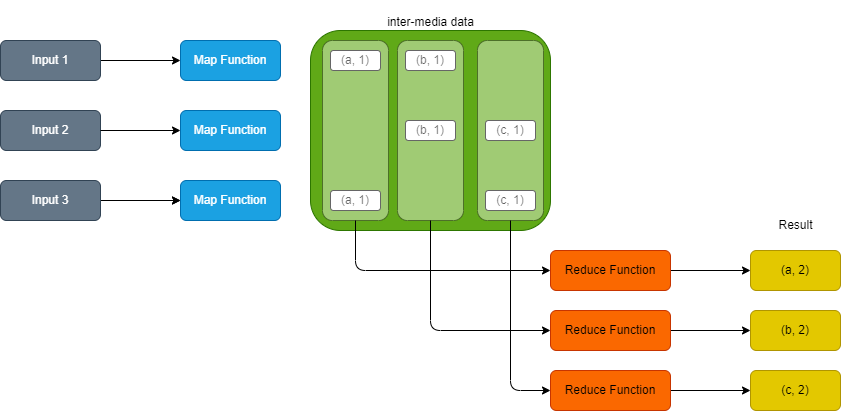
MapReduce:
- 将工作拆解为多个
Map任务和多个Reduce任务. Map任务负责从输入中根据MapFunction筛选出需要的数据, 称为中间数据(inter-media data), 传给Reduce任务.Reduce汇聚多个Map任务传递的中间数据, 然后统计出对应的结果.
2 并发
本课程使用 go 来实现, 因此讨论 goroutine.
为什么要并发?
- IO 并发
- 并行化程序
- 便利性(如: 定时任务)
并发的替代: 事件驱动(Event-Driven), 但是只能 IO 并发, 不能使用 CPU 的并行资源.
在 go 中, 可以使用 --race 参数来大致判断是否存在并发冲突的问题.
3 GFS
GFS == Google File System
分布式系统存储面临的问题:
- 性能(Performance) --> 系统分片(Sharding)
- 分片带来不可预测的错误(Faults) --> 容错系统(Fault Tolerance)
- 容错系统 --> 副本(Replication)
- 副本 --> 一致性问题(In Consistency)
- 一致性保证 --> 低性能(Low Performance)
得出结论: 如果要强一致性, 会与分布式系统的性能要求相悖.
3.1 GFS 的解决方案
希望达到的效果:
- 存储量大, 访问速度快(Big & Fast)
- 全局的(Global)
- 文件分片存储(Sharding)到不同的磁盘/机器中
- 错误自动恢复(Automatic Recovery)
- 单数据中心
- 内部使用
- 针对大文件顺序读取(Big Sequential Access)
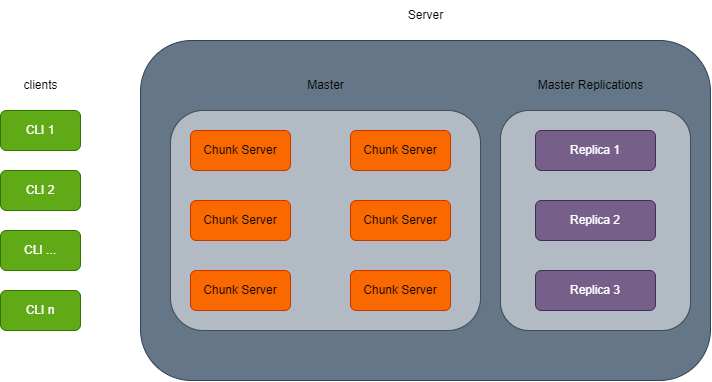
块服务器(Chunk Server):
- 一个 Master 由很多个 Chunk Server 组成.
- 一个 Chunk Server 中保存文件的连续片段, 每个片段大小为 64MB.
- 一个大文件会被切分(Sharding)为多个连续片段, 保存在不同的 Chunk Server 中.
在 GFS 中, 寻找特定的数据块(Chunk)需要两张表, 姑且称之为 FileMap 和 ChunkMap.
用 Go 来描述两张表:
type FileName string
type ChunkHandlerId int64
// a file is sharding into many pieces and stored into many chunk servers
type FileMap map[FileName][]ChunkHandlerId // nv
type ChunkHandler struct {
// a chunk has some replications
ChunkServers []ChunkServer // v
// each chunk has a version
Version int64 // nv
// the primary chunk in the replications
Primary int64 // v
// expiration time of a primary chunk
LeaseExpiration // v
}
type ChunkMap map[ChunkHandlerId]ChunkHandler
由于 GFS 工作时数据存储在内存, 所以需要将内存中的数据进行持久化. 为了保证内存中的数据不丢失, 会使用 Log 和 CheckPoint 来进行保证.
如果有对数据的写入操作, Log 就会向文件中写入一条日志; 并且会定期创建 CheckPoint. 使用文件而不是数据库作为日志, 因为文件的顺序写入能力更好, 每次只需要将一条或几条日志追加到文件的结尾即可. CheckPoint 则是对某一时刻 GFS 系统的快照进行持久化, 避免因为 Log 日志过多而导致恢复很慢.
这里可以参考 redis 中的 AOF 持久化和 RDB 持久化.
上面两张表中, 有一部分数据是需要持久化的, 用 nv (non-volatile)标识; 另一部分不需要持久化的数据, 用 v 标识.
每次 GFS 重启, 都会重新与所有的 Chunk Server 建立联系, 并且选出对应的 Primary 节点; 每个 Primary 节点会从 Master 中获取租约, 如果租约到期但是没有续约, 可能会重新更换 Master 节点.
GFS 文件的读取:
- FileName, FileOffset --> Master.
- Master --> ChunkHandler, List of ChunkServers(可能选择网络速度最快/版本最新的副本进行读取).
缓存读取结果(局部性原理, 可能多次从 64MB 的块中读取数据). - Client --(ChunkHandlerId, FileOffset)--> ChunkServer
ChunkServer --(Data)--> Client.
如果要读取的数据正好横跨两个 Chunk, 那么 Master 会分两次获取两个 Chunk 中的数据, 然后以一个数据的形式返回给 Client.
GFS 文件的写入:
仅针对在文件尾部追加内容的方式(记录追加).
- Master 需要能够找到对应文件的最后一个 Chunk 所在的 ChunkServer List 以及 List 中的 Primary 节点. 如果当前没有 Primary 节点, 需要先找到持有最新副本的 ChunkServer 集合, 在其中选择一个作为 Primary 节点.
- 然后 Master 将版本号递增, 写入磁盘.
- Master 通知 Primary 和 Secondary(其余的具有最新版本号的) 节点, 更新版本号, 并将版本号写入磁盘.
- Master 告知 Client Primary 和 Secondary 节点的信息.
- Client 将要追加的信息发送给 Primary 和所有的 Secondary 节点, 节点将其缓存到缓冲区, 发送 ack. (这里应该是发送给某一个节点, 然后 Master 内部按照某种最小跨域交换机的处理, 分发给其余节点)
- 当 Client 收到所有节点的 ack, 就通知 Primary 节点.
- Primary 节点选择应该追加到哪一个 offset, 然后通知所有的 Secondary 将缓存中的内容写入到 offset 后.
- 节点将内容写入, 如果写入成功, 返回给 Primary "OK", 如果不成功, 返回 "NO".
- Primary 需要收到所有节点返回的 "OK", 再返回 "SUCCESS" 给 Client, 否则返回 "FAIL". "FAIL" 代表有 0 个或者多个副本成功写入了数据.
- 如果返回 "FAIL", Client 需要重新开始和 Master 的通信以确定最新的 ChunkServer 及其内容. Client 会一直请求直至返回 "SUCCESS".
4 容错
这一节我们思考如何通过副本来增加容错性, 示例为 VMWare Fault-Tolerance 系统.
GFS 的 Replication 只是在高层面(应用层面)对有限的数据进行复制, 很多系统的复制系统都是这么做的. 而 VMWare FT 不同, 他需要做到在低层面的完整数据复制, 来保证上层应用在任何地方都能够运行.
我们先了解一下 VMWare 的系统结构:
VMWare 直接安装在物理机上, 通过 Virtual Machine Monitor(VMM) 完成硬件与其中虚拟系统的交互. 在虚拟机中, 可以启动多个不同的操作系统, 并且独立的运行不同的应用程序.
下图中, 两台机器都安装了 VMWare, 并且分为 Primary 和 Backup, Backup 为 Primary 的镜像. Client 1 通过 LAN 发送网络包给 Primary 节点, VMM 收到网络中的包, 向对应的子系统发送模拟网络包, 同时, 向 Backup 从节点发送和它收到的网络包相同的包, 使从节点的数据操作和主节点保持一致. 完成后, 主节点向 Client 1 返回数据包, 而 Backup 节点的 VM 知道自己只是从节点, 不需要返回包, 因此直接在 VMM 中删除该数据包.
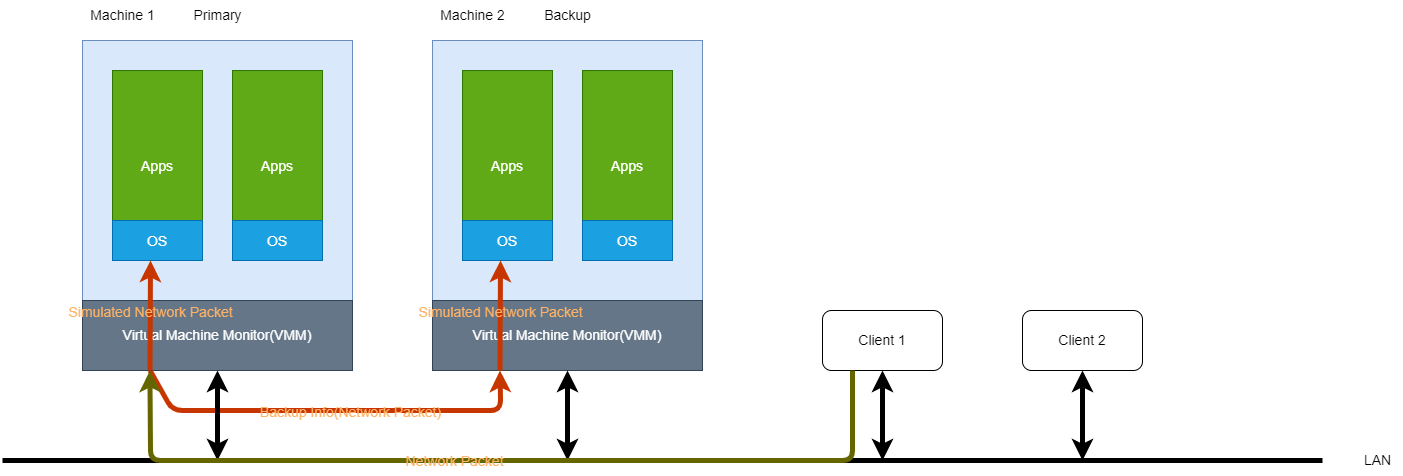
主从节点之间的信息流称为 Log Channel, 其中传递的数据是 Log Entry. 主节点收到中断将产生一条 Log Entry, 写入到 Log Channel 中.
从节点会定时从 Log Channel 获取日志(如 100 次/s). 如果在一定时间内没有收到任何日志, 说明 Primary 节点可能已经宕机, 那么该节点就不再继续执行来自主节点的指令, 也不会再等待 Log Channel 中的事件, 而是变成一个可以独立接收和执行指令的自由节点, 可以接收网络中的请求并输出返回的信息.
如果主节点发现 Log Channel 中的信息一直没有被消费, 那么会停止向从节点发送备份日志, 并认为该节点已经宕机.