Java.lang 包
Java.lang 包
1 Object
public class Object {
private static native void registerNatives();
static {
registerNatives();
}
// 返回 调用类 的 被 static synchronized 修饰的 类型擦除对象
public final native Class<?> getClass();
// 返回对象的哈希值, 对 HashMap 进行支持
public native int hashCode();
// 比较对象是否相同, 具有 自反、对称、传递、一致性
// 只有引用的内存地址相同才判定相同
// 如果要重写此方法, 需要同时重写 hashCode 方法, 目的是维持 hashCode 方法的一般约定(相等的对象必须有相同的哈希码)
public boolean equals(Object obj) {
return (this == obj);
}
// 返回当前对象的复制对象
// 拷贝要求:实现 Cloneable 接口
// 拷贝方式:浅拷贝
protected native Object clone() throws CloneNotSupportedException;
// 返回对象的字符串表示形式, 建议所有类都重写此方法
// 返回 类实例名称@对象哈希码的无符号十六进制表示
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
// 唤醒在该对象的监视器上等待的(某一个)线程, 进入线程就绪状态
public final native void notify();
// 唤醒在该对象的监视器上等待的所有线程, 进入线程就绪状态
public final native void notifyAll();
// 让线程进入等待状态, 直到被 notify()/notifyAll() 唤醒, 或者超过指定等待时间
public final native void wait(long timeout) throws InterruptedException;
// 同上
public final void wait(long timeout, int nanos) throws InterruptedException {
if (timeout < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
}
if (nanos > 0) {
timeout++;
}
wait(timeout);
}
// 使线程进入长期等待状态, 直到且只能被 notify()/notifyAll() 唤醒
public final void wait() throws InterruptedException {
wait(0);
}
// 当确定没有对该对象的引用的时候, 由垃圾收集器在对象上进行调用
protected void finalize() throws Throwable { }
}
2 String
2.1 基础
String 是由 final 修饰的类, 实现了 Serializable, Comparable, CharSequence 接口.
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
}
由于 String 类被 final 修饰, 其具有如下特征:
- 不可被继承, 类成员方法都默认为
final方法 String类一旦被创建, 就无法被改变, 对String类的操作都不会影响到原对象.
也就是说, 一切对 String 类的更改操作都会产生新的 String 对象.
String 类中维护了如下成员变量:
private final char value[];
private int hash;
private static final long serialVersionUID = -6849794470754667710L;
private static final ObjectStreamField[] serialPersistentFields =
new ObjectStreamField[0];
String类由于被final修饰, 无法被更改, 所以value使用char[]保存.hash值将用于类中的hashCode()方法的计算, 暂且不表.serialVersionUID用作序列化ID.serialPersistentFields用于表明序列化时哪些字段需要被默认序列化.
String 类的创建可以有以下方法:
- 字面量赋值:
String str = "String"; - 连接符赋值:
String str = "Str" + "ing"; - 使用
new创建对象:String str = new String("String"); - 还可以使用其他方法:
- 使用
clone()方法 - 使用反射
- 使用反序列化
- 使用
String 被设置为不可变的原因主要是为了保证"效率"和"安全性".
- 如果
String能被继承, 由于它的高度使用率, 会导致程序性能降低. - 由于有字符串常量池的存在, 不可变的
String为管理和优化字符串常量池中的对象提供了更有效的途径. - 在安全性方面, 由于使用字符串的场景非常多, 将其设置为不可变可以有效防止字符串被篡改.
String在HashMap,HashTable中经常作为key被使用. 由于不可变的设计, 使得 JVM 底层很容易在缓存String对象的时候缓存其hashcode, 大大提高了执行效率.
2.2 深入 String
2.2.1 String 的创建
在深入理解 String 之前, 先了解一下 Java 的内存区域. Java 在运行时, 数据区域主要包括:
参考 Java 内存区域
- 方法区 (Method Area)
- 堆区 (Heap)
- 本地方法栈 (Native Method Stack)
- 虚拟机栈 (VM Stack)
- 程序计数器 (Program Counter Register)
对于 String 类来说, 有一个字符串常量池(StringPool), 在 HotSpot VM 中使用 StringTable 实现.
StringTable 是一个 Hash 表, 其中存储驻留字符串的引用, 也就是堆中的某些字符串实例被 StringPool 引用之后, 就等同被赋予了驻留字符串的身份.
StringPool在每个 HotSpot VM 中的实例只有一份, 被所有类共享.
注释: 驻留字符串即被双引号括起来的字符串
StringPool 中的内容是在类加载完成, 经过验证, 准备阶段之后在堆中生成的字符串对象实例的引用值而. 具体的实例对象是在堆中开辟的一块空间存放的.
下面我们讨论String的创建过程, 以创建"String"举例:
String name_1 = "String";
String name_2 = "String";
String name_3 = new String("String");
name_1 == name_2; // true
name_1 == name_3; // false
如果
String使用赋值创建, 字面量"String"在赋值前就已经被放入StringPool中, 所以name_1,name_2引用都指向StringPool中的"String"对象,name_1 == name_2.如果使用
new进行创建, 则会先在堆中创建一个String对象, 然后判断StringPool中是否存在字符串的常量, 如果不存在则在常量池中创建常量; 如果存在则什么都不做. 所以name_3指向堆中的对象.
注意: 使用
+运算符拼接字符串效率很低, 底层会自动调用StringBuilder对象进行append().
String 类中维护了一个 intern() 方法, 其主要功能如下:
- 如果
StringPool中包含调用该方法的字符串, 就直接返回常量池中的字符串. - 如果不包含, 就将该
String对象存入常量池, 返回该String对象的引用.
String a1 = new String("AA") + new String("BB");
System.out.println("a1 == a1.intern() " + (a1 == a1.intern())); // true
String test = "ABABCDCD";
String a2 = new String("ABAB") + new String("CDCD");
String a3 = "ABAB" + "CDCD";
System.out.println("a2 == a2.intern() " + (a2 == a2.intern())); // false
System.out.println("a2 == a3 " + (a2 == a3));
System.out.println("a3 == a2.intern() " + (a3 == a2.intern())); // true
我们再来看String的创建过程,
- 使用字面量创建
- 常量池中没有值: 直接创建字符串并保存到
StringPool中. - 常量池中有值: 需要判断字面量值是真正的字符串值还是引用, 如果是字符串值, 就将局部变量指向字符串常量池中的值; 如果是引用, 就指向引用指向的地方.
- 常量池中没有值: 直接创建字符串并保存到
new创建- 首先在堆中创建一个对象, 然后在
StringPool中创建一个指向堆中对象的引用.
- 首先在堆中创建一个对象, 然后在
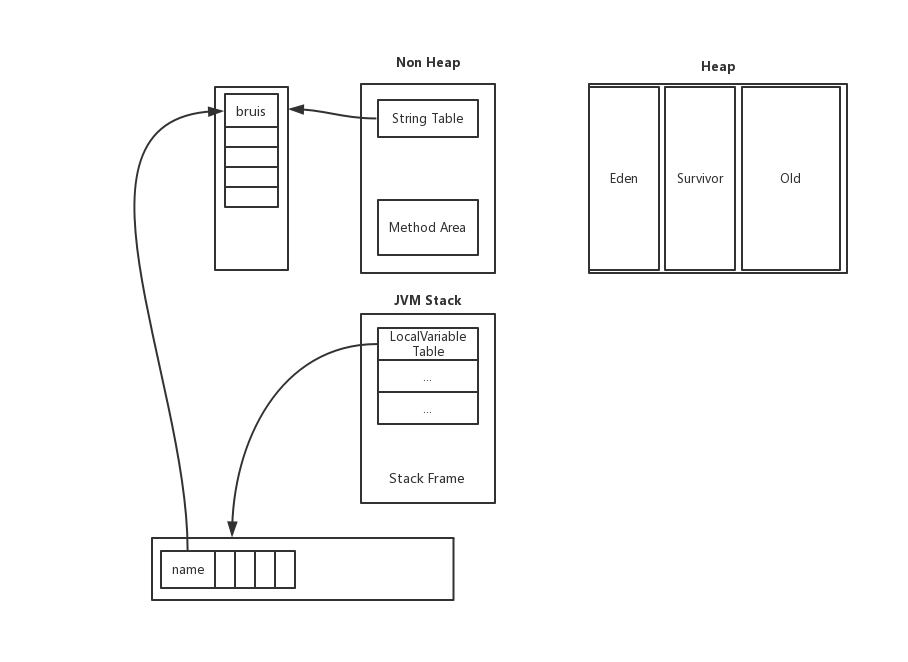
对于以字面量形式创建的字符串, JVM 会在编译期时对其进行优化, 并将字面量值存放在 StringPool 中. 运行期时在虚拟机栈栈帧中的局部变量表里创建一个 name 局部变量, 然后指向 StringPool 中的值, 如图:
如果是引用类型的字面量创建的字符串, 过程如下: 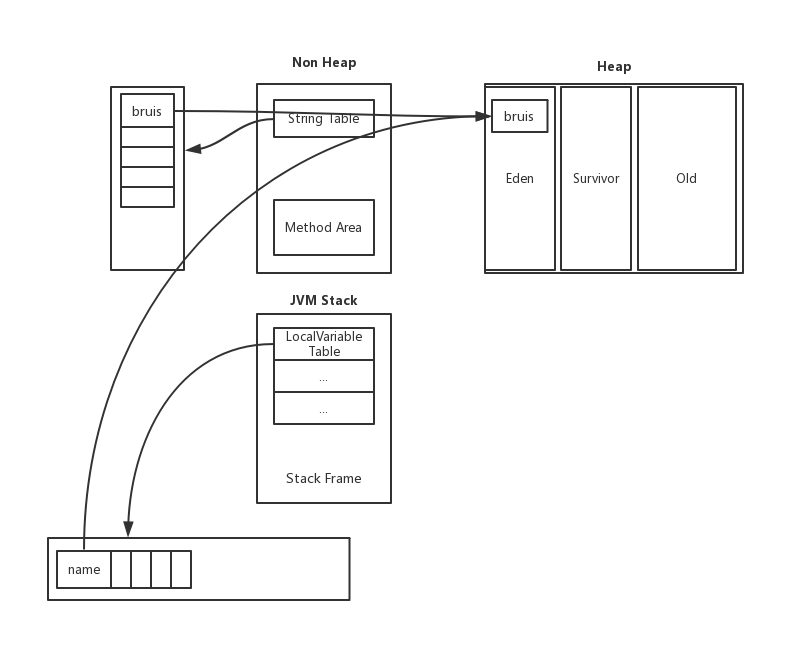
针对于编译器优化, 可以总结以下两点:
- 常量可以被认为运行时不可改变, 所以编译时被以常量折叠方式优化.
- 变量和动态生成的常量必须在运行时确定值, 所以不能在编译期折叠优化.
2.2.2 String 类的方法
equals() 方法源码如下:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
由源码可知, equals() 方法会先比较字符串对象的地址, 如果相同就返回 true; 如果不同就比较字符串的内容, 也就是遍历 char[] 比较每一个char是否相同
hashCode() 源码如下:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
String 类中的 hash 值默认为 0, 如果字符串为空, 则 hash = 0; 第一次调用 hashCode() 方法时, 会根据公式计算出对应的 hash 值并保存在 hash 属性中. Hash 的算法如下:
总结:
关于
equals()和hashCode()方法, Java中有如下规范:
- 如果两个对象
equals(), 则它们的 hashcode 一定相等.- 如果两个对象不
equals(), 它们的 hashcode 可能相等.- 如果两个对象的 hashcode 相等, 则它们不一定
equals().- 如果两个对象的 hashcode 不相等, 则它们一定不
equals().
compareTo() 是 String 对 Comparable 接口的实现, 其源码如下:
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
return len1 - len2;
}
compareTo() 会进行两个比较:
- 最小长度的字符串按字符比较
- 如果前者没有比较出结果, 就比较字符串长度, 返回字符串长度差值.
startsWith() 源码如下:
public boolean startsWith(String prefix) {
return startsWith(prefix, 0);
}
public boolean startsWith(String prefix, int toffset) {
char ta[] = value;
int to = toffset;
char pa[] = prefix.value;
int po = 0;
int pc = prefix.value.length;
// Note: toffset might be near -1>>>1.
if ((toffset < 0) || (toffset > value.length - pc)) {
return false;
}
while (--pc >= 0) {
if (ta[to++] != pa[po++]) {
return false;
}
}
return true;
}
如果该字符串从 toffset 开始的字串以 prefix 为前缀, 就返回 true, 否则返回 false.
endsWith() 实际调用了 startsWith() 方法:
public boolean endsWith(String suffix) {
return startsWith(suffix, value.length - suffix.value.length);
}
比较和 suffix 相同位数的该字符串的末尾字串是否相同.
indexOf() 源码如下:
public int indexOf(int ch) {
return indexOf(ch, 0);
}
public int indexOf(int ch, int fromIndex) {
final int max = value.length;
if (fromIndex < 0) {
fromIndex = 0;
} else if (fromIndex >= max) {
// Note: fromIndex might be near -1>>>1.
return -1;
}
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) {
// handle most cases here (ch is a BMP code point o
// negative value (invalid code point))
final char[] value = this.value;
for (int i = fromIndex; i < max; i++) {
if (value[i] == ch) {
return i;
}
}
return -1;
} else {
return indexOfSupplementary(ch, fromIndex);
}
}
返回参数字符 ch 在该字符串从 fromIndex 开始的字串中第一次出现的 index
private int indexOfSupplementary(int ch, int fromIndex) {
if (Character.isValidCodePoint(ch)) {
final char[] value = this.value;
final char hi = Character.highSurrogate(ch);
final char lo = Character.lowSurrogate(ch);
final int max = value.length - 1;
for (int i = fromIndex; i < max; i++) {
if (value[i] == hi && value[i + 1] == lo) {
return i;
}
}
}
return -1;
}
indexOfSupplementary() 方法对两个字节字符的参数 (如: emoji) 进行处理, 逻辑大致相同.
public static boolean isValidCodePoint(int codePoint) {
// Optimized form of:
// codePoint >= MIN_CODE_POINT && codePoint <= MAX_CODE_POINT
int plane = codePoint >>> 16;
return plane < ((MAX_CODE_POINT + 1) >>> 16);
}
isValidCodePoint() 方法用于判断代码点是否为一个有效的 Unicode 代码节点.
>>> 表示无符号右移.
split() 方法较为复杂, 源码如下:
public String[] split(String regex, int limit) {
char ch = 0;
if (((regex.value.length == 1 &&
".$|()[{^?*+\\".indexOf(ch = regex.charAt(0)) == -1) ||
(regex.length() == 2 &&
regex.charAt(0) == '\\' &&
(((ch = regex.charAt(1))-'0')|('9'-ch)) < 0 &&
((ch-'a')|('z'-ch)) < 0 &&
((ch-'A')|('Z'-ch)) < 0)) &&
(ch < Character.MIN_HIGH_SURROGATE ||
ch > Character.MAX_LOW_SURROGATE))
{
int off = 0;
int next = 0;
boolean limited = limit > 0;
ArrayList<String> list = new ArrayList<>();
while ((next = indexOf(ch, off)) != -1) {
if (!limited || list.size() < limit - 1) {
list.add(substring(off, next));
off = next + 1;
} else { // last one
//assert (list.size() == limit - 1);
list.add(substring(off, value.length));
off = value.length;
break;
}
}
// If no match was found, return this
if (off == 0)
return new String[]{this};
// Add remaining segment
if (!limited || list.size() < limit)
list.add(substring(off, value.length));
// Construct result
int resultSize = list.size();
if (limit == 0) {
while (resultSize > 0 && list.get(resultSize - 1).isEmpty()) {
resultSize--;
}
}
String[] result = new String[resultSize];
return list.subList(0, resultSize).toArray(result);
}
return Pattern.compile(regex).split(this, limit);
if 判断中第一个括号先判断一个字符的情况, 并且这个字符不是任何特殊的正则表达式. 如果要根据特殊字符来截取字符串, 则需要使用 \\ 来进行字符转义.
(regex.value.length == 1 &&
".$|()[{^?*+\\".indexOf(ch = regex.charAt(0)) == -1)
if 判断中, 第二个括号判断有两个字符的情况, 并且如果这两个字符是以\开头的, 并且第二个字符不是字母或者数字的时候.
(regex.length() == 2 && regex.charAt(0) == '\\' &&
(((ch = regex.charAt(1))-'0')|('9'-ch)) < 0 &&
((ch-'a')|('z'-ch)) < 0 && ((ch-'A')|('Z'-ch)) < 0)
判断完之后, 在进行第三个括号判断, 判断是否为两字节的 Unicode 字符.
(ch < Character.MIN_HIGH_SURROGATE ||
ch > Character.MAX_LOW_SURROGATE)
下面来看主要处理逻辑, 逻辑切分与解释都在注释中标出:
int off = 0;
int next = 0;
boolean limited = limit > 0;
ArrayList<String> list = new ArrayList<>();
// 如果剩余字串还能被切分的情况
while ((next = indexOf(ch, off)) != -1) {
if (!limited || list.size() < limit - 1) {
list.add(substring(off, next));
off = next + 1;
} else {
// 最后一个切分, 直接添加剩余字串
// 执行到此处, list.size() == limit - 1, 执行完毕后 list.size() == limit
list.add(substring(off, value.length));
off = value.length;
break;
}
}
// If no match was found, return this
if (off == 0)
return new String[]{this};
// 用于没有限制或者限制数量大于实际能切分的数量的情况, 将剩余字串添加到list
if (!limited || list.size() < limit)
list.add(substring(off, value.length));
// Construct result
int resultSize = list.size();
// 处理无限制的切分情况下尾部有空串("")的情况, 直接删除掉尾部所有的空串
if (limit == 0) {
while (resultSize > 0 && list.get(resultSize - 1).isEmpty()) {
resultSize--;
}
}
String[] result = new String[resultSize];
return list.subList(0, resultSize).toArray(result);
对于入参limit, 可以总结一下:
limit > 0,split()方法最多把字符串拆分成limit个部分.limit == 0,split()方法会拆分匹配到的最后一位regex, 并删除掉末尾的空串.limit < 0,split()方法会根据regex匹配到的最后一位, 如果最后一位为regex, 则多添加一位空字符串;如果不是则添加regex到字符串末尾的子字符串.
举例如下:
String str = "what!is!!!";
System.out.println(Arrays.toString(str.split("!"))); // [what, is]
System.out.println(Arrays.toString(str.split("!", -1))); // [what, is, , , ]
System.out.println(Arrays.toString(str.split("!", 3))); // [what, is, !!]
System.out.println(Arrays.toString(str.split("!", 5))); // [what, is, , , ]
3 AbstractStringBuilder
AbstractStringBuilder 是 StringBuilder, StringBuffer 的父类, 实现了 Appendable 以及CharSequence接口.
AbstractStringBuilder 中大量使用了 System.arrayCopy() 方法.
AbstractStringBuilder 维护了两个属性: value 和 count.
// 保存字符串.
char[] value;
// 保存字符串长度, 被 length()方法直接返回.
int count;
AbstractStringBuilder 有两个构造器:
有参构造用于在初始化时创建一个长度为 capacity 的 char[]. StringBuilder 和 StringBuffer 的构造器都会调用此方法进行初始化.
AbstractStringBuilder() {
}
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
下面我们关注 AbstractStringBuilder 的扩容原理:
private void ensureCapacityInternal(int minimumCapacity) {
if (minimumCapacity - value.length > 0) {
value = Arrays.copyOf(value,
newCapacity(minimumCapacity));
}
}
ensureCapacityInternal() 方法确保每次执行添加操作都有足够的空间. 判断出需要扩容时, 会调用 newCapacity() 方法来确定新的容量大小.
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private int newCapacity(int minCapacity) {
int newCapacity = (value.length << 1) + 2;
if (newCapacity - minCapacity < 0) {
newCapacity = minCapacity;
}
return (newCapacity <= 0 || MAX_ARRAY_SIZE - newCapacity < 0)
? hugeCapacity(minCapacity)
: newCapacity;
}
扩容规定为: 原容量 * 2 + 2, 如果足够使用, 就使用扩容后的容量; 如果还是不够使用, 就直接使用传入数据作为扩容后的容量.
确定扩容后的容量后, 会进行溢出判断, 如果容量溢出, 会调用 hugeCapacity() 方法进行溢出处理.
private int hugeCapacity(int minCapacity) {
// overflow
if (Integer.MAX_VALUE - minCapacity < 0) {
throw new OutOfMemoryError();
}
return Math.max(minCapacity, MAX_ARRAY_SIZE);
}
如果容量不小于 Integer.MAX_VALUE, 会直接抛出异常; 否则返回 minCapacity 和 MAX_ARRAY_SIZE 的最大值.
了解完扩容, 再来看看容量优化: 容量优化主要由 trimToSize() 方法完成, 源码如下:
public void trimToSize() {
if (count < value.length) {
value = Arrays.copyOf(value, count);
}
}
如果实际使用的空间小于扩容后占用的空间, 就会缩减空间到当前最小空间.调用此方法后, 可能会影响 capacity() 方法的返回值.
注意:
AbstractStringBuilder的两个方法:length()和capacity()方法返回的值可能不同.
length()方法直接返回count的值, 是当前保存字符的数量;而
capacity()方法返回的是value.length, 也就是数组的大小;
相比之下, AbstractStringBuilder 的 setLength() 方法是比较暴力的:
public void setLength(int newLength) {
if (newLength < 0)
throw new StringIndexOutOfBoundsException(newLength);
ensureCapacityInternal(newLength);
if (count < newLength) {
Arrays.fill(value, count, newLength, '\0');
}
count = newLength;
}
该方法会首先保证 char[] 容量大小至少为 newLength (即可能进行扩容), 然后和当前大小进行比较:
- 如果大于当前大小, 就将扩容后的空字符都用
'\0'填充. - 如果小于当前大小, 就令
count = newLength, 也就表示保存的数据长度只有newLength,newLength后面的数据会被抛弃掉.
举例如下, 注意每次 setLength() 会不会触发扩容以及填充/舍弃数据:
StringBuilder sb = new StringBuilder();
sb.append("hello");
System.out.println(sb.toString()); // hello
System.out.println("size:" + sb.length()); // 5
System.out.println("capacity" + sb.capacity()); // 16
sb.setLength(2);
System.out.println(sb.toString()); // he
System.out.println("size:" + sb.length()); // 2
System.out.println("capacity" + sb.capacity()); // 16
sb.setLength(20);
System.out.println(sb.toString()); // he\0\0\0\00\0\0\00\0\0\00\0\0\0\0\0
System.out.println("size:" + sb.length()); // 20
System.out.println("capacity" + sb.capacity()); // 34
sb.setLength(77);
System.out.println("size:" + sb.length()); // 77
System.out.println("capacity" + sb.capacity()); // 77
再来看看 charAt() 方法, 源码如下:
public char charAt(int index) {
if ((index < 0) || (index >= count))
throw new StringIndexOutOfBoundsException(index);
return value[index];
}
直接返回对应 index 的字符.
setCharAt() 方法同理.
append() 相关方法也比较简单, 源码如下:
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
首先判断是否需要扩容, 如需要就进行扩容. 然后调用 String#getChars() 方法将 str 追加到 value 数组中, 然后更新 count.
String#getChars() 被广泛用于将字符串添加到扩容后的数组中, 源码如下:
public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin) {
if (srcBegin < 0) {
throw new StringIndexOutOfBoundsException(srcBegin);
}
if (srcEnd > value.length) {
throw new StringIndexOutOfBoundsException(srcEnd);
}
if (srcBegin > srcEnd) {
throw new StringIndexOutOfBoundsException(srcEnd - srcBegin);
}
System.arraycopy(value, srcBegin, dst, dstBegin, srcEnd - srcBegin);
}
实则也是调用 System.arrayCopy() 方法进行的.
注意: 需要注意的是,
appendNull()添加的是"null"字符串, 而被添加的参数为boolean时, 添加的时"true"/"false".
subString() 方法调用了 new String() 来进行操作:
public String substring(int start, int end) {
if (start < 0)
throw new StringIndexOutOfBoundsException(start);
if (end > count)
throw new StringIndexOutOfBoundsException(end);
if (start > end)
throw new StringIndexOutOfBoundsException(end - start);
return new String(value, start, end - start);
}
最后看一下 reverse() 方法, 源码如下:
public AbstractStringBuilder reverse() {
boolean hasSurrogates = false;
int n = count - 1;
for (int j = (n-1) >> 1; j >= 0; j--) {
int k = n - j;
char cj = value[j];
char ck = value[k];
value[j] = ck;
value[k] = cj;
if (Character.isSurrogate(cj) ||
Character.isSurrogate(ck)) {
hasSurrogates = true;
}
}
if (hasSurrogates) {
reverseAllValidSurrogatePairs();
}
return this;
}
使用两个指针 j 和 k. 关于中心对称. 从中间开始一边向两边遍历, 一边交换. 就完成了翻转.
4 StringBuilder
看完 AbstractStringBuilder, 我们来看看他的子类 StringBuilder, 其中的核心功能都已经在 AbstractStringBuilder 中定义了. 同时 StringBuilder 还实现了 Serializable 接口.
先来看看构造方法, 会调用 AbstractStringBuilder 构造方法:
public StringBuilder() {
super(16);
}
public StringBuilder(int capacity) {
super(capacity);
}
public StringBuilder(String str) {
super(str.length() + 16);
append(str);
}
public StringBuilder(CharSequence seq) {
this(seq.length() + 16);
append(seq);
}
构造器有三个主要情况:
- 如果是无参构造, 则默认设置容量为16;
- 如果传入容量, 就将容量设置为传入容量的大小;
- 如果传入
String或CharSequence, 就设置为传入串的长度 + 16, 并且添加传入的串.
再来看一些常用的方法:
public StringBuilder insert(int index, char[] str, int offset, int len) {
super.insert(index, str, offset, len);
return this;
}
public StringBuilder reverse() {
super.reverse();
return this;
}
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
可以看到, 很多方法都是直接调用了父类 AbstractStringBuilder 的方法, 然后返回 this.
但是由于父类的 toString() 方法是抽象方法, 所有这里重写了 toString() 方法.
5 StringBuffer
看完线程不安全的 StringBuilder, 再来看看线程安全的 StringBuffer, 同样也是继承了父类 AbstractStringBuilder, 并且实现了 Serializable以及 CharSequence 接口.
问题:
为什么
AbstractStringBuilder已经实现了CharSequence接口,StringBuffer还要再实现一次CharSequence接口?
StringBuffer 的大多数方法都是在 StringBuilder 的方法基础上加上 synchronized 关键字, 用于保证线程安全.
StringBuffer 还有一点不同的是, 它加入了缓存机制--toStringCache 属性.
private transient char[] toStringCache;
public synchronized String toString() {
if (toStringCache == null) {
toStringCache = Arrays.copyOfRange(value, 0, count);
}
return new String(toStringCache, true);
}
public synchronized StringBuffer reverse() {
toStringCache = null;
super.reverse();
return this;
}
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
可以看到 toStringCache 会缓存最后一次 toString() 的结果, 并且每一次对 value 的修改, 都会重置 toStringCache 为 null;
如果 toStringCache 有效(非空), 则当调用 toString() 方法时直接返回 toStringCache 的值,而不需要使用消耗性能的 Arrays.copyOfRange() 方法.
6 ThreadLocal
ThreadLocal 是一个是由 JDK 提供的一个用于存储每个线程本地副本信息的类. 我们先看看官方注释:
官方注释:
这个类用于提供线程本地变量, 这些变量和普通的变量不同, 因为每个线程通过访问
ThreadLocal的get()或者是set()方法都会获得其独立的、初始化的变量副本.ThreadLocal实例通常是希望将线程独有的状态(例如用户ID/交易ID) 线程中的私有静态字段进行关联, 即将线程独有的状态存储到线程中.每个线程都会持有一个指向
ThreadLocal变量的隐式引用, 只要线程还没有结束, 该引用就不会被 GC. 但当线程结束后并且其他地方没有对这些副本进行引用, 则线程本地实例的所有副本都会被 GC.
看完官方文档, 我们可以了解到 ThreadLocal 的适用场景, 大致可分为以下两类:
- 用于存储线程本地的副本变量, 即为了做到线程隔离.
- 用于确保线程安全.
不过 ThreadLocal 的适用场景还不止这些:
线程资源持有(线程隔离)
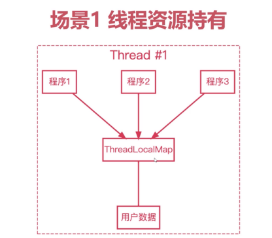
ThreadIsolationUsingThreadLocal.png 在 Web 程序中, 每一个线程就是一个
session, 不同用户访问程序会通过不同的线程来访问, 通过ThreadLocal来保证同一个线程的访问获取到的用户信息是相同的, 同时不会影响到其他用户的信息. 所以ThreadLocal可以很好的保证线程之间的隔离性.线程资源一致性: 这个场景在
JDBC中有使用到, 在JDBC内部会通过ThreadLocal来保证线程资源的一致性.我们都知道, 每个 HTTP 请求都会在 web 程序内部生成一个线程, 而每个线程去访问 DB 的时候, 都会从数据库连接池获取一个
Connection连接用于进行数据库交互. 那么当一个 HTTP 请求进来, 该请求在程序内部调用了不同的服务, 在这个调用链中每次请求一个服务都需要进行一次数据库交互, 那就有了一个如何确保在请求过程中和数据库交互的事务状态一致的问题. 如果同一个请求的调用链中Connection都不同, 那么就没法进行事务控制了. 因此JDBC通过ThreadLocal来确保每次的请求都和同一个Connection对应, 确保一次请求链中都调用的同一个Connection, 这就是线程资源一致性.线程安全: 基于
ThreadLocal存储在Thread中作为本地副本变量的机制, 保证每个线程都可以有用自己的上下文, 确保了线程安全. 相较于加锁(Synchronized,Lock),ThreadLocal的效率更高.分布式计算
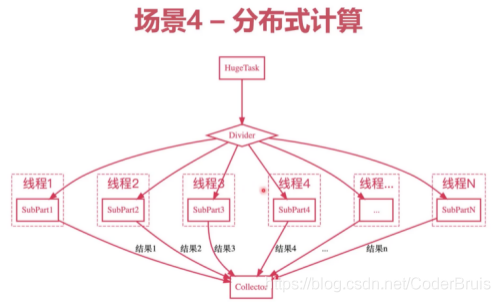
DistributedComputingUsingThreadLocal 在分布式计算中, 每个线程都计算出结果后, 最终通过将
ThreadLocal存储的结果取出, 来获得所有线程的计算结果.在
SqlSessionManager中的使用private ThreadLocal<SqlSession> localSqlSession = new ThreadLocal(); public Connection getConnection() { SqlSession sqlSession = (SqlSession) this.localSqlSession.get(); return sqlSession.getConnection(); }SqlSessionManager对SqlSession的存储是通过ThreadLocal实现的.在
getConnection()时实际就是去ThreadLocal中获取SqlSession连接.在 Spring 的
TransactionContextHolder中的使用其实就是在分布式事务中需要一个
context资源上下文来存储一次分布式事务需要共享的数据, 便于分布式事务共同处理(如: 业务回滚等).
了解完 ThreadLocal 的使用场景, 我们来看看它的源码:
在看源码之前提出几个问题:
ThreadLocal是怎么保证了线程隔离的?ThreadLocal注释中提到的隐式引用是什么? 有什么作用?ThreadLocal为什么要用到隐式引用? 而不用强引用?- 据说
ThreadLocal会发生内存泄漏? 什么情况下会发生内存泄漏? 如何避免内存泄漏? - 使用
ThreadLocal有什么需要注意的点?
我们先来看看其中使用的数据结构:
// 用于 ThreadLocal 内部 ThreadLocalMap 数据结构的哈希值, 用于降低哈希冲突.
private final int threadLocalHashCode = nextHashCode();
// 原子操作生成哈希值, 初始值为0.
private static AtomicInteger nextHashCode = new AtomicInteger();
// 用于进行计算出 threadLocalHashCode 的哈希值.
private static final int HASH_INCREMENT = 0x61c88647;
// 返回下一个哈希值, 让哈希值散列更均匀.
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
下面来看 TreadLocal 最重要的一个数据结构--ThreadLocalMap:
/**
* ThreadLocalMap其实就是一个用于ThreadLocal的自定义HashMap, 它和HashMap很像. 在其内部有一个自定义的Entry类,
* 并且有一个Entry数组来存储这个类的实例对象. 类似于HashMap, ThreadLocalMap同样 的拥有初始大小, 拥有扩容阈值.
*/
static class ThreadLocalMap {
/*
* 可以看到, Entry类继承了WeakReference类, 它的含义是弱引用, 即JVM进行GC * 时, 无论当前内存是否够用, 都会把被WeakReference指向的对象回收掉.
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
// ThreadLocalMap 的初始大小
private static final int INITIAL_CAPACITY = 16;
// 用于存储 Entry 的数组
private Entry[] table;
// 当前 Entry[] 的大小
private int size = 0;
// 扩容阈值, 扩容阈值为初始大小值的三分之二.
private int threshold; // Default to 0
private void setThreshold(int len) {
threshold = len * 2 / 3;
}
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
private static int prevIndex(int i, int len) {
return ((i - 1 >= 0) ? i - 1 : len - 1);
}
简略讲解一下 Entry 继承 WeakReference 的原因:
- 是为了在
Thread线程在执行过程中, key 能够被 GC 掉, 从而在需要彻底 GC 掉ThreadLocalMap时, 只需要调用ThreadLocal的remove()方法即可. - 如果是用的强引用, 虽然
Entry到Thread不可达, 但是和Value还有强引用的关系, 是可达的, 所以无法被 GC 掉.
虽然 Entry 使用的是 WeakReference 虚引用, 但 JVM 只是回收掉了 ThreadLocalMap 中的 key, 但是 value 和 key 是强引用的(value也会引用 null), 所以 value 是无法被回收的, 所以如果线程执行时间非常长, value 持续不 GC, 就有内存溢出的风险. 所以最好的做法就是调用 ThreadLocal 的 remove() 方法, 把 ThreadLocal.ThreadLocalMap 给清除掉.
注意:
ThreadLocalMap的 key 就是ThreadLocal对象, value 就是Entry中保存的value, 通过Entry的构造方法来建立起ThreadLocal对象和value的虚引用, 这就是一对Entry.
每一个 Thread 都有一个自己的 ThreadLocalMap 变量, 我们来看看 Thread 中的源码定义:
ThreadLocal.ThreadLocalMap threadLocals = null;
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
可以发现维护了两个 ThreadLocalMap 对象, threadLocals 是属于自己的 map, inheritableThreadLocals 是用于父子线程间 ThreadLocal 变量的传递.
回到 ThreadLocal 的源码中, 我们看看 set() 和 get() 方法:
// ThreadLocal中的 set() 方法
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
// 将当前线程传入, 作为 ThreadLocalMap 的引用, 创建出 ThreadLocalMap
createMap(t, value);
}
// ThreadLocalMap中的 set() 方法
private void set(ThreadLocal<?> key, Object value) {
// 初始化Entry数组
Entry[] tab = table;
int len = tab.length;
// 通过取模计算出索引值
int i = key.threadLocalHashCode & (len-1);
// 如果 ThreadLocalMap 中 tab 的槽位已经被使用了, 则寻找下一个索引位
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
// 如果 key 引用被回收了, 则用新的 key-value 来替换, 并且删除无用的 Entry
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
// 清楚那些 get() 为空的对象, 然后进行 rehash.
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
public T get() {
// 获取当前线程 t
Thread t = Thread.currentThread();
// 获取线程 t 中的 ThreadLocalMap
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
// 如果没有获取到ThreadLocalMap, 则初始化一个ThreadLocalMap
return setInitialValue();
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
// 初始化
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
以上便是存储和获取 ThreadLocal 方法, 下面我们来看看如何清除 ThreadLocal, 防止内存泄漏, 也就是 remove() 方法.
// ThreadLocal 的 remove() 方法
public void remove() {
// 获取当前线程中的 ThreadLocalMap
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
// ThreadLocalMap 中的 remove() 方法
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
// 通过取模获取出索引位置
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
// 清除没用的槽位以及 null 插槽, 并且对其进行重新散列
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// 将插槽位置的键和值都设置为null
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// 遇到null的插槽, 重新散列计算哈希值
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
看到这里可能还是比较疑惑 Thread, ThreadLocal, ThreadLocalMap 的关系, 在这里给一张图:
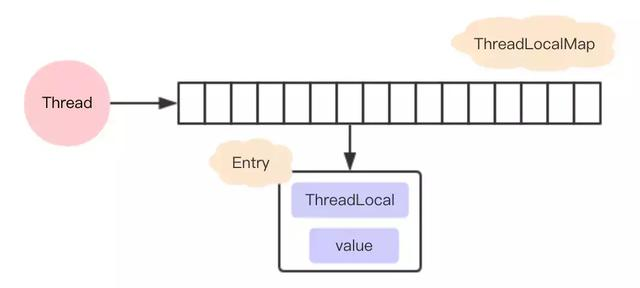
ThreadLocalMap 为了对外界透明, 不被外界干扰, 所以通过 ThreadLocal 的封装进行相关操作.
Thread 拥有 ThreadLocalMap 的属性, 但是不能直接操作 ThreadLocalMap, 所以需要借助 ThreadLocal 进行操作.
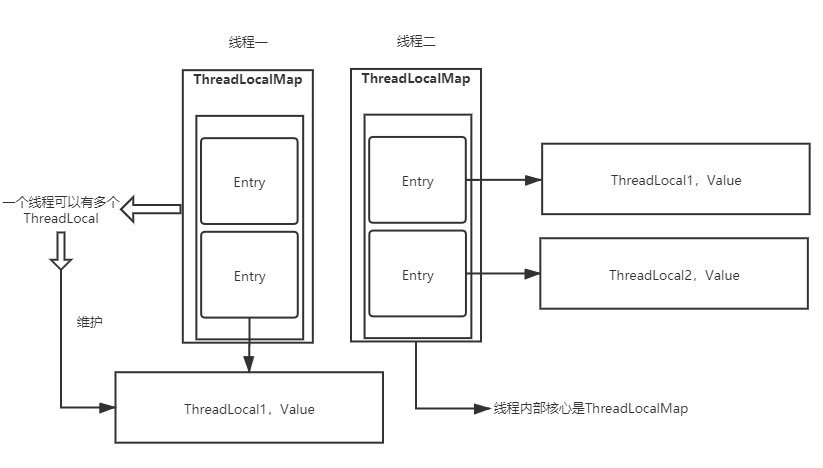
一个 Thread 可以有多个 ThreadLocal, 用于维护不同的 Value.
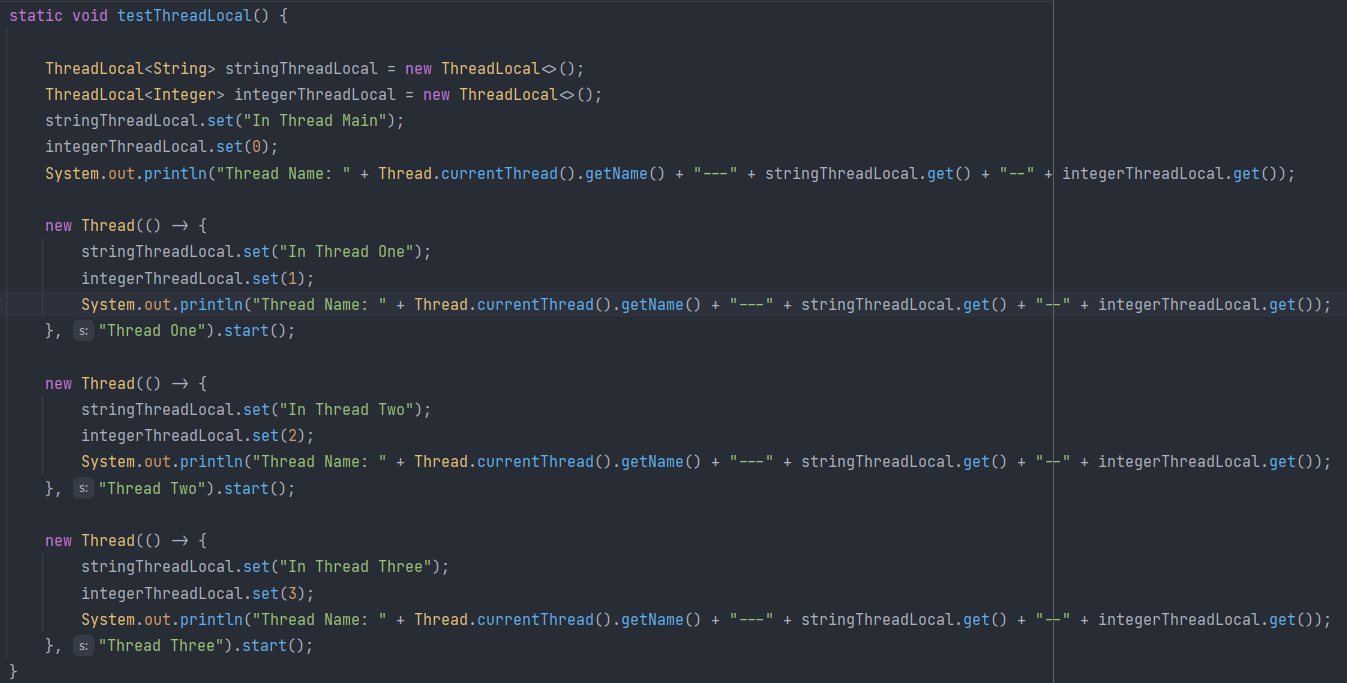
看看平时的用法:
输出为:
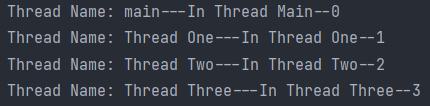
说明不同线程通过 ThreadLocal 获取 ThreadLocalMap 中的数据是互不干扰的.